CRTC Hearing Text Analysis
This is a brief summary of the text analysis performed on a series of transcripts published by the CRTC between April 11 and April 28, 2016.
The purpose of this post is twofold:
- describe how to read the Jupyter Notebook
- highlight key findings of the analysis
How to Read the Jupyter Notebook
Jupyter Notebook is an interactive web-based tool that combines live code, data visualizations, and rich text and media. The notebooks provide researchers with an agile programming environment that supports reproducible research and the ability to have code, visualization and analysis in one accessible platform. The interactive Jupyter Notebooks are easily shared with others via GitHub, but they can also be downloaded as static PDF or HTML files.
You can read a Jupyter Notebook even if you can’t read code; in fact, this is one reason why they exist.
All of the code blocks in a Jupyter Notebook are found in outlined grey boxes, with a numeric identifier beside it that looks like this: In [6]. Sometimes the code will have words that appear in different colours, with different formatting (usually bold/italics). Without worrying too much about the colours right now, the only thing you need to know about the code blocks is that any text that appears with a # in front of it is known as a comment. Comments are generally used to describe the code, but sometimes a # is used to ‘turn off’ the code so it doesn’t run. See two examples below:


Text describing the code and showing the results of the code is found everywhere but the grey boxes. This is the text to pay the most attention to. The text that shows the results of the code is in what I can only describe as a typewriter style font (like Courier), while the text that describes the code is not. In the image below, the text on the top shows the result of the code, while the text on the bottom is descriptive text.

TL:DR If you don’t want to read the code, avoid looking at the text in the grey boxes.
Key Findings of the Analysis
You can find the complete notebook here on GitHub. I’m summarizing the findings from the notebook below, with screenshots.
I’ve made the assumption that one of the concepts of interest involves the word guarantee. I’ve run the text analysis to focus on this word, but it’s very easy for me to generate more results with a different word. Just let me know.
The word guarantee and it’s variations appear with the greatest frequency in the transcript dated April 15, 2015.

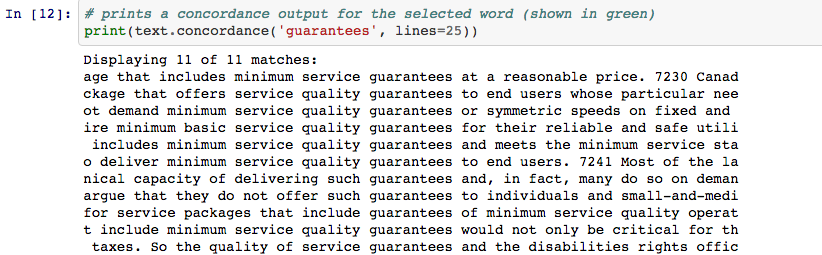
Guarantees is the most common of these occurrences. Here is a ‘Key Word In Context’ concordance that shows its use. You can read this section of my thesis to learn more about concordances.
The following findings were generated after the removal of stopwords. Check here for the complete list of words, most of which come from the Cornell list found here.
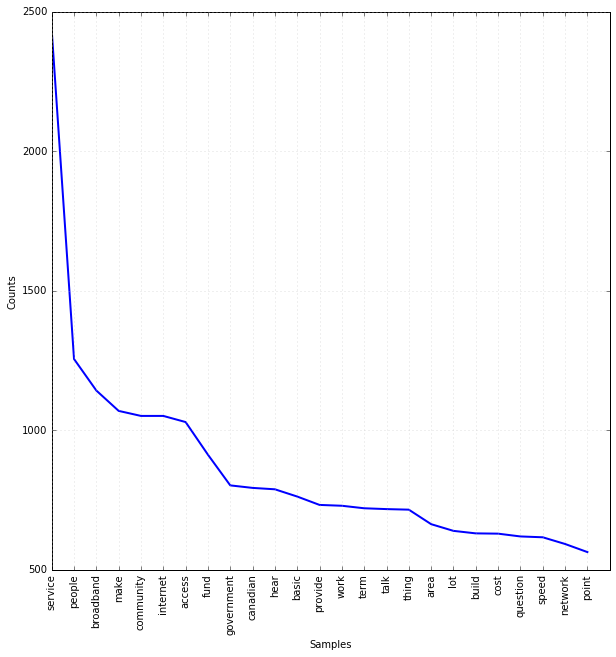
Here’s a look at the word frequency of the top 25 words used in the text as a whole. The most commonly used word is service, followed by people and broadband.
Another fun frequency finding involves the ten most common bigrams found in the text. While guarantee doesn’t appear here, one of Michael’s favourite phrases does appear: market forces! The text has been lemmatized…that’s why it’s market force, rather than forces.

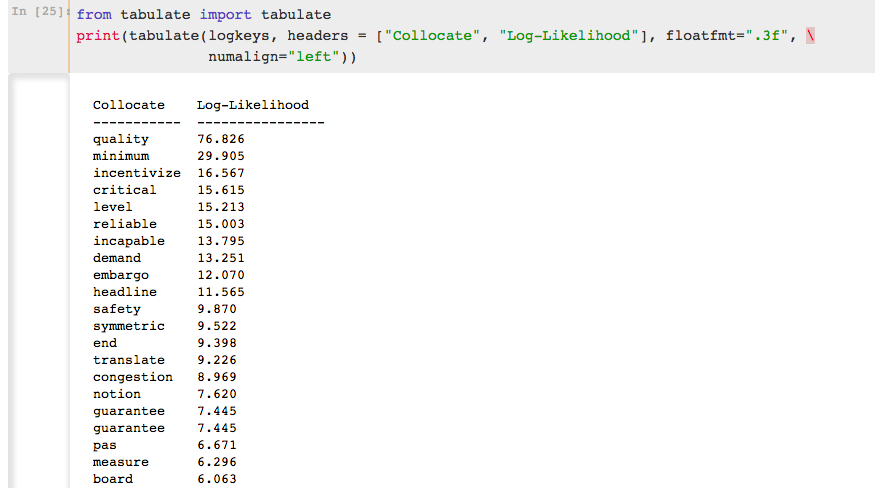
And finally, here is a list of the most significant collocated words appearing with guarantee. The test used here is the Log Likelihood. The Log-likelihood ratio calculates the size and significance between the observed and expected frequencies of bigrams and assigns a score based on the result, taking into account the overall size of the corpus. The larger the difference between the observed and expected, the higher the score, and the more statistically significant the collocate is. The Log-likelihood ratio is my preferred test for collocates because it does not rely on a normal distribution, and for this reason, it can account for sparse or low frequency bigrams. It does not over-represent low frequency bigrams with inflated scores, as the test is only reporting how much more likely it is that the frequencies are different than they are the same. The drawback to the Log-likelihood ratio is that it cannot be used to compare scores across corpora.
The word most significantly collocated with guarantee is quality, followed by minimum and incentivize. It is extremely important to note here that words will appear twice in the following list. As the ngrams can appear both before and after the word, care must be taken to identify duplicate occurences in the list below and then combine the totals. Therefore, the list below is a sample. Please refer to the notebook for the complete list, and calculate accordingly.
Let me know if you have any questions about this work, or if you’d like the code run on another word. It takes about 5 seconds to run all of the code from start to finish.
I’n still working on segmenting the text by speaker. I’m hoping to have that finished this week.